Digitisation, Digital transformation, Datafication
With the rise of computational methods for humanities research, as well as the increasing born-digital materials out there, archives around the globe are experiencing a digital turn. Compared to practices years ago where the focus is predominantly on digitising physical objects, nowadays practices cover all aspects of record-keeping – creation, capturing, organising and pluralising – through a combination of digitisation, digital transformation, and datafication (Gilliland, 2014).
A clear switch in mindset can be seen in the digital turn where archivists start to seek more holistic and future-oriented solutions for their existing and potentially new materials, not only trying to collect in the fullest manner possible, preserving natively to the complexity of their form but also bridging the gap between archive and end-users, critically attuned to the possibilities and perils that come with the use (Padilla, 2017).
More specifically, the digital turn happens on three major levels:
Infrastructure – Changes that happened on this level mostly focus on issues relating to accessibility and management of archives, such as digital access, appraisal, handling of sensitive information;
Coverage – This part includes attempts to foster inter-collection collaboration and compatibility, as well as methods and standards to archive new materials such as social media contents, aiming to create less biassed and more representative collections;
Content – This is where digitisation and most of the content understanding and description happen. The goal is to transform the material into the digital space for better accessibility and to generate structured descriptors that could eventually describe as much as possible the original from a range of perspectives possible.
The purpose of the digital turn is to ultimately enable a future-facing archive with greater accessibility, better coverage, and finer granularity.
With the primary interest of research using digital methods and archives remains textual (Fickers, 2018), numerous works of such can be seen in textual based collections such as manuscripts, legal documents, and newspapers. However, few have been done on audiovisual archives. To further examine the digital turn for audiovisual archives, we will be looking closely into three topics: the existing standards for audiovisual contents; a conceptual model for Understanding AV contents from the top-down; and practices with AV archives in the digital age.
Standards for AV contents description
Compared to structured or even unstructured textual contents, audiovisual ones are not particular-to to the default computational infrastructures to interpret and access. The semantics are well hidden under multimodality, creating barriers to managing and using such archives (Tesic, 2005). Although the recent advances in natural language processing and computer vision have enabled many content level extraction and analysis tools, offering the content and semantic level descriptors to the table, only a few are developed for or applied to audiovisual archives. Attempts of using such methods on audiovisual archives yield very preliminary results too – providing nothing much beyond what is available through standard full-text search (Brock, 2022). However, the importance of descriptors for audiovisual contents, especially at scale, remains.
Describing archival contents using different descriptors is not news. Various metadata or descriptor standards were created without considering the development of computational tools, and covering not only content level information. Whether the annotation is manually or automatically created, the goal of such standards is to regulate and standardise what to describe when it comes to an archive system. These descriptors, in essence, are not to replace the original, but to provide a vehicle for more digital and data-centric management and application.
Similarly to every other domain, it is not practical to have a single standard to address everything in the audiovisual world. Existing metadata standards were created with different focuses on their use and coverage (Smith, 2006).
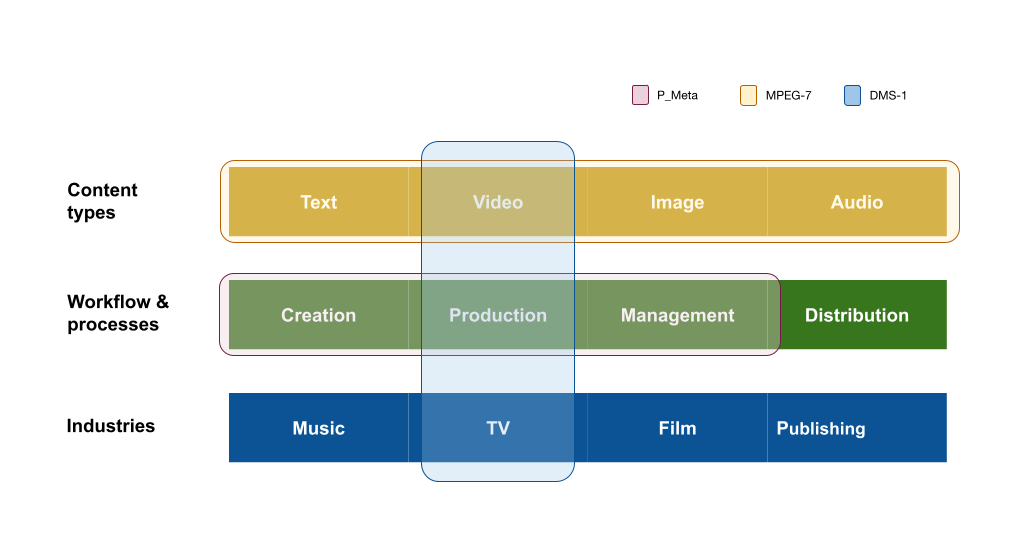
As can be seen in Fig.1, MPEG-7 has a focus on content level description and addresses all media types from text to video. DMS-1, on the other hand, covers some content level stuff but is combined with production level metadata. It is very industry-focused, specifically designed for the TV & broadcast companies to use as an interchange layer between archives. P_Meta, similar to DMS-1 is designed specifically for the TV & broadcast industry, but unlike DMS-1, it does not contain the content level descriptors but mainly describes the overall workflow of the industry, covering not only the production but also content creation and lifecycle management.
In recent practices, more attempts for flexible and situated standards are built upon the foundation of these broad and large standards, mainly to cope with the ever-growing specific use cases that emerged from the day-to-day. For example, markup languages NewsML and SportsML are developed to enhance the exchangeability for broadcasting news content and sports features. Looking into the culture and heritage sector, although not focusing on audiovisual contents, there are attempts on creating case-specific standards, some through mapping MPEG-7 to CIDOC CRM (Angelopoulou, 2011), some merging Dublin Core to create a connection to culture and heritage specific contents (Kosch, 2002; Thornely, 2000).
Although these attempts show the potential of creating a situated standard specifically for audiovisual archives in the cultural and heritage sector, describing the content for the unique needs of memory institutions dealing with moving images, they mostly come from a technical or problem-solving perspective. The quest of constructing a standard, or in other words, a data model for audiovisual contents in the cultural and heritage sector is never examined holistically.
A conceptual model for understanding audiovisual contents from top-down
To decide what we can describe, we first need to understand what is an audiovisual archive and its contents in the cultural and heritage setting.
The content in question, from analogue films to clips on social media, from newsreels to feature films, is essentially anything that has the appearance of movement. And similar to any other material, such as a painting or a book, it serves its purpose to record and mirror the complexity of humanities’ past and present.
Previous studies look at contents in audiovisual archives from different perspectives, some treat contents as archival objects and talk about preservation and distribution, some explore rich semantic meanings and use them as references to study the past (Steinmetz, 2013; Wiltshire, 2017; Knight, 2012; Tadic, 2016). Roughly speaking, we could look at audiovisual contents from three broad dimensions – Archival; Affective & Aesthetic; Social & Historical.
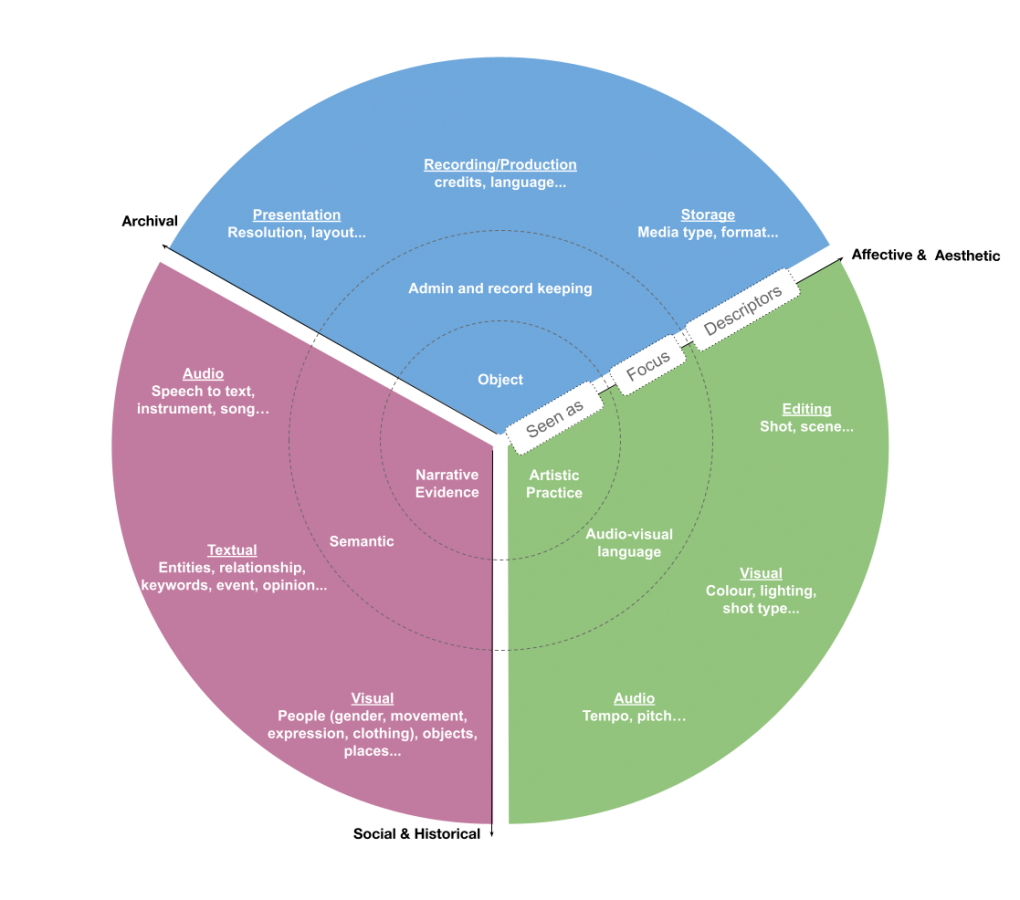
In the archival dimension, every audiovisual content is regarded as an archival object, and descriptors corresponding to that would very much be focusing on the admin level, benefiting the record-keeping process including organising, management, and dissemination; Moving into the affective and aesthetic dimension, contents are regarded as some sort of artistic or cultural practice, and the focus is shifted to the audiovisual language, and its cultural or artistic indication; When the social and historical dimension is what in question, contents become narratives and pieces of evidence of past happenings and semantics (literal or not) out of these contents emerged to be the core.
It is not hard to further expand the model within each dimension, detailing different categories of descriptors, examples of descriptors from existing standard or innovative ones, as well as the corresponding methods for getting them (Fig. 2).
The purpose of summarising such a thinking model is to help draw the connection between lower-level descriptors (annotations, metadata, or whatever people call them), potential methods for acquiring such descriptors, and higher-level purposes built upon a single or a combination of audiovisual content dimensions. Ideally, the content descriptors should work as a middle ground, opening up the gate and guiding people with expertise in computational methods to link their works to the purposeful and meaningful interpretation of the contents, as well as people with curatorial objectives to break down their thoughts into different dimensions to engage more comfortably with different technologies out there possible to serve their goals.
Practices with AV archives in the digital age
Moving on to the practical level, there are some (although not as much as textual or image-based) projects working closely to the idea of the digital turn with a focus on audiovisual materials. The model constructed above is used as a guide to facilitate the process of pinpointing these attempts within the overall theoretical framework.
One major theme for such projects, broadly speaking, is to enhance accessibility and searchability
Some are doing so by working on the semantics, building pipelines for extracting semantic entities from the multimodality of the content or linking existing ones to a connected graph.
Compared to the traditional audiovisual archive experiences powered by basic metadata (production, format, keyword, etc.), these attempts improve the searchability of the archive by adding the textual search terms from the content level. These practices, adding descriptors from multiple dimensions, also enable the exploration in alternative organisations (graph-based for example) of an audiovisual archive for better connectivity and exploration of the content.
Several projects take the path of platform building. Indiana University (IU) Libraries, in collaboration with New York Public Library and digital consultant AVP, is developing an open-source software system AMP, that enables the efficient generation of metadata to support discovery. Using tools like OCR, and applause/instrument detection to add semantic descriptors to their data. Similarly, the CLARIAH (Common Lab Research Infrastructure for the Arts and Humanities) is a distributed research infrastructure for the humanities and social sciences in the Netherlands and provides annotation and automatic tools for enhancing semantics. The Media Ecology Project at Dartmouth also aims to provide a new infrastructure for access to archival data, as well as manual and automated methods for enhancing the annotation of audiovisual contents.
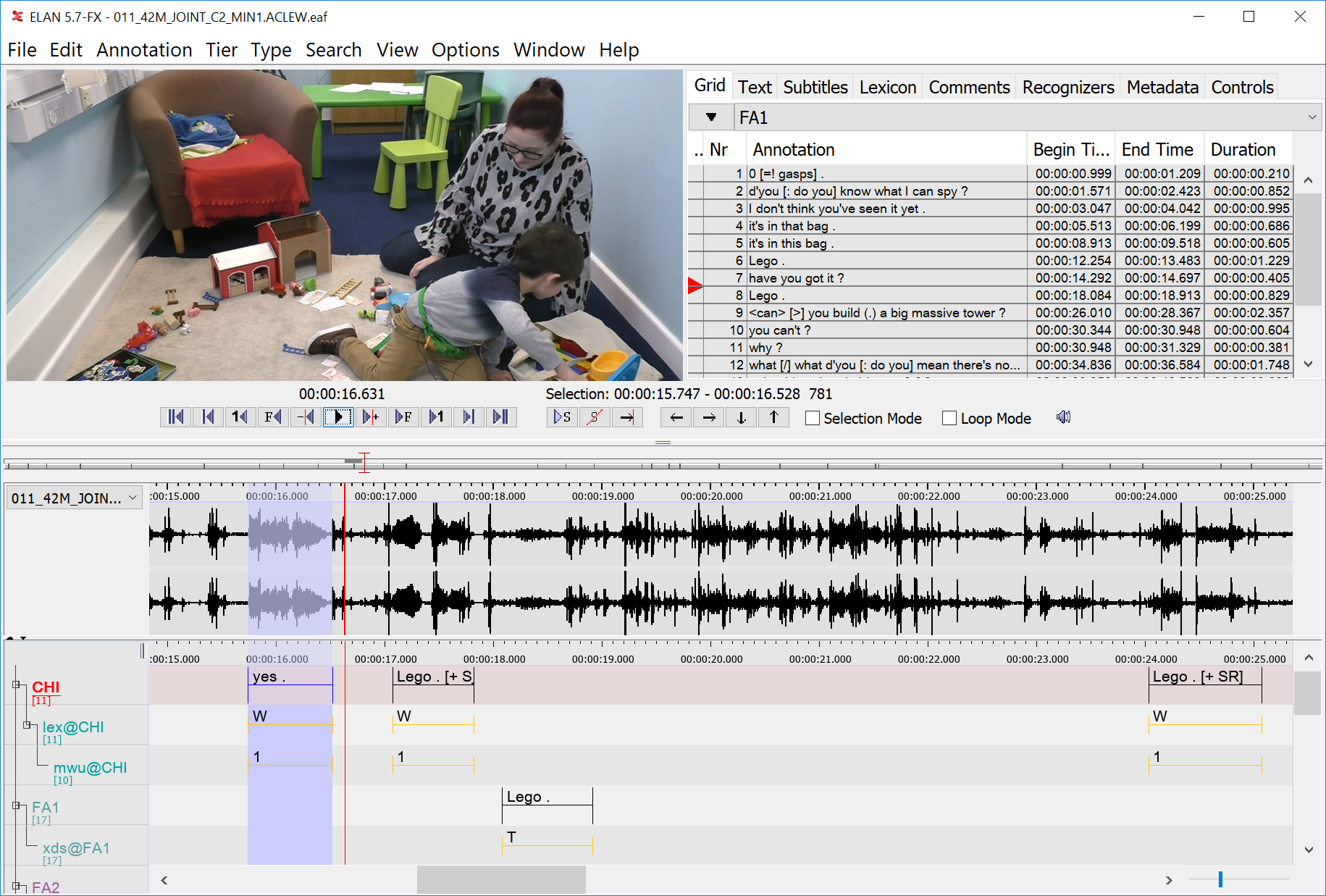
Some projects focus on building tools and methods. ELAN (Fig.3) from the language archive in the Netherlands is a manual annotation tool for audio and video recordings, which allows unlimited semantic annotations in the form of a sentence, word or gloss, a comment, translation or a description of any feature observed in the media. Automated methods are constantly put forward and groups like the Distant Viewing Lab (Fig.4) are busing aggregating them to the field of cultural industries, lowering the bar for recognition and segmentation tools, as well as finding potential use cases with experiments. With the recent development in deep learning, researchers have moved into other semantics to extract. For example the research from Stanford University and the University of California, Berkeley focused on pose extraction and its potential for comparative choreography analysis (Broadwell, 2021). Another group of researchers from Leiden University is looking at the possibility of automated sign language annotation (Fragkiadakis, 2021)

Other projects are busing utilizing semantic information to create graph-based interfaces for access. Jazz Luminaries (Fig.5 & video) benefit from the rich semantic connections between artists and scores from the rich archive of Montreux Jazz Festival and build an interactive experience based on that. The project invites audiences to explore and remix the archive using the network that is built to reorganise the archive. More recently, Videograph (Rossetto, 2021), a video retrieval system proposed by a team of researchers from the University of Zurich, will also explore the potential of accessing audiovisual materials through a semantic metadata powered and graph-based interface.

Some have taken a different direction, working on introducing often ignored perspectives to add to the descriptions.
Instead of focusing on the semantic entities in the text, audio, and moving images, these projects choose to work with the audiovisual language. Looking at the different filming and editing techniques and their presence in the audiovisual contents, the role of colour and audio features. Working on the intersection between audiovisual languages and their aesthetic and affective meanings, the aim of such projects is often to enhance the audiovisual archive experience from a more abstract and artistic perspective.
Some efforts were made on building controlled vocabularies for audiovisual languages for future annotation. The Columbia File Language Glossary is one of the early works under this category. As an educational tool for the study of film, it features professionally curated key terms, corresponding clips, as well as visual and audio commentaries. The Kinolab, as well as Critical Commons, are also similar attempts for annotating audiovisual materials using controlled or lose vocabularies in terms of its audiovisual languages, as well as techniques used.
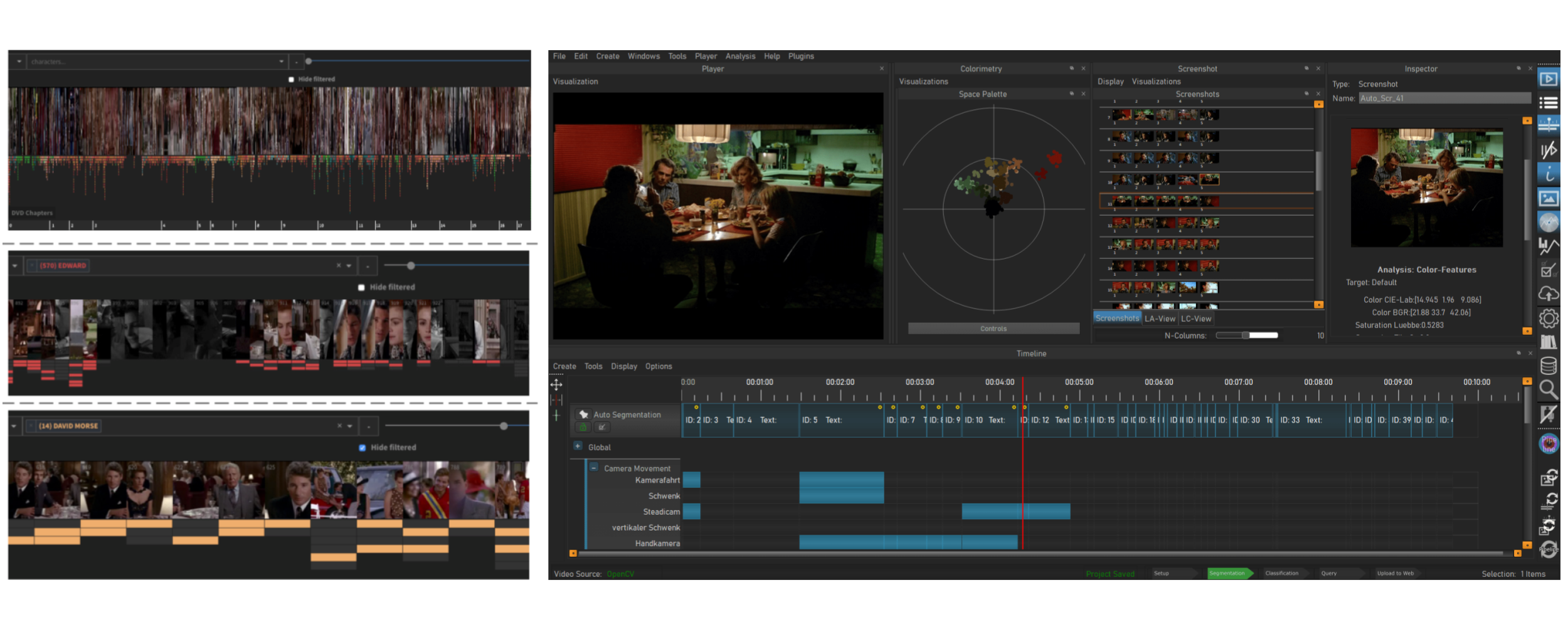
Aside from the projects working on a dictionary of literal terms to use for the artistic language used, some projects focus on a specific aspect of the audiovisual language. The MovieBarcodes (Fig.6 Left) project suggests colour as an additional quantitative parameter for movie analysis and describes an information system that allows scholars to search for movies via their specific colour distribution. Also on the colour front, VIAN (Fig.6 Right) supported by the ERC Advanced Grant FilmColors research project, is a professional colour analysis tool that enables the streamlined processing for colourimetry on multiple levels. enables insights into the ‘stylistic, expressive and narrative dimensions of film colours’. Polifonia, a 3M€ project funded by the EU Horizon 2020 Programme focuses to recreate the connections between music, people, places and events from the sixteenth century to the modern-day, works on methods to extract information on music patterns and music objects intrinsic features. The Sensory Moving Image Archive (Fig.7) project works on multiple fronts, using colour, shape, texture and movement to connect all clips and create an alternative experience for accessing and exploring the audiovisual archive without searching for literal items, encouraging serendipity discoveries.
The other major theme is on exploring the use and application of an archive and its multidimensional descriptors
Different from the previous theme where the focus is on creating a more accessible and explorable archive, practices under this theme mostly aim at utilising the archive to create sense-making experiences to express and explain.
Some of these projects have very specific topics. BBC Northern Ireland’s Rewind Archive consists of 13,000 clips including news reports, documentaries and lifestyle programmes from the 1950s to the 1970s. To provide a glimpse of what life was like in the old times and an opportunity to relive the timeline with regard to the complexity of history, this archive is carefully curated annotated with periods, locations, and themes. In RED – a spatial film installation (Fig.8) hosted in the Deutsches Filmmuseum, the use of the colour red is examined through a curated collection of film clips covering topics such as protagonists, objects, spaces, effects, and direction. The exhibition, using a single element in the audiovisual languages, explained the role of the aesthetic and narrative elements in films.

On the other hand, several projects are on the quest of exploring complex and sometimes unexplainable topics through interactive experiences or some sort of synesthetic translation. Artist practices with audiovisual archives such as the Suprise Machine (Fig.9 Upper left), The third AI (Fig.9 Upper right), and the Machine Hallucination (Fig.9 Lower) apply deep learning models on contents and reduce them to latent representations. Some use Umap or equivalent to display contents clustered, so that audience and see the changes happening moving around. Others use generative models to create content with similar characteristics from the latent space. And the unexplainable – style, machine understanding – are revealed through the comparison of the originals to the new contents. On the research end, many studies also work on translating the subtle feelings and complex concepts to something easier to perceive – understanding gentrification through the change of urban sound samples (Martin, 2021), as well as translating the ambience of something visual into something we can hear through image sonification (Graham, 2020; Kramer, 2021).

Co-curating and co-creating are heated topics for current curatorial practices. The annotated archive is the foundation for interactive, free, and inviting experiments. These practices benefit from the higher granular and connected contents and embrace diverse and personal narratives in the archive. One classic work on this topic is the T_VISIONARIUM II (Fig.10), which uses computationally segmented scene clips as well as annotations of emotion, expression, physicality and scene structure, speed, gender, colour. This processed archive and the interactive experience allow the viewer to both search and recombine 500 simultaneously looping video streams, creating an emergent narrative of their own. The BBC story former lives in a browser. However, the same principle applies – benefiting from annotated segments of videos, as well as an interactive interface, the web application allows users to create flexible, multithreading, and responsive stories.

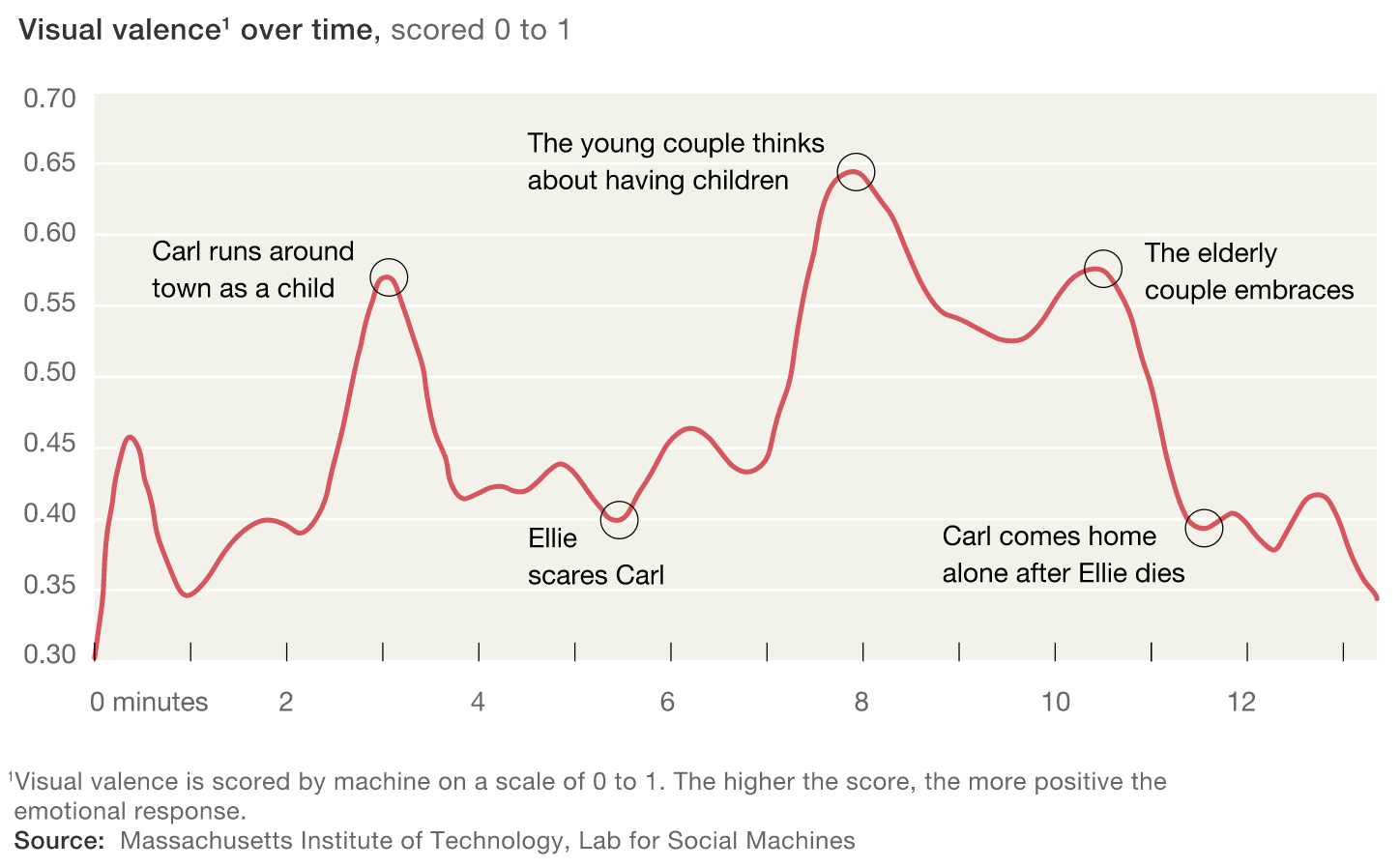
Different dimensions of descriptors are also used in more commercial settings, sometimes as a replacement for the original content, enabling faster and easier studies on the relationship between the content and the audience, providing insights for commercial problems like video recommendation and audience engagement. Storyline (Fig.11), a project between McKinsey & Company’s Consumer Tech and Media team and the MIT Media Lab explores the possibility of this project reducing a video story to a visual valence curve using a combination of audiovisual features. The curve is used for grouping content and studying the relationship between audience engagement and emotional responses. Similarly, researchers are also working on using visual features based on MPEG-7 standard to recreate the Mise-En-Scène for movies and trying to crack the recommendation and personalisation problem using such a set of features (Deldjoo, 2017).
It is also worth noticing that there are efforts on the validation and infrastructure fronts to facilitate audiovisual archives’ digital turn.
With the increasing application of computational methods for annotation of the audiovisual content in the archival settings, the validation and benchmarking of existing models and methods for related tasks emerged. MediaEval is a benchmarking initiated by media scholars, offering challenges in artificial intelligence on multimodal data and aiming to develop and evaluate methods dedicated to the retrieval, access, exploration and analysis. BenchmarkSTT, a tool offered by the European Broadcasting Union, aims to benchmark the performances of methods for speech-to-text solutions. Industry leaders like Nextflix work hard on providing a more efficient and flexible infrastructure for containing annotations in the digital era. The Netflix Media Database is a database design and implementation to “persist deeply technical and rich metadata about various media assets at Netflix and to serve queries in near real-time using a combination of lookups as well as runtime computation.”
From the perspective of Narrative from the long tail
Traditionally, scholars regard narratives as spatiotemporal sequences of events. However, it seems too native as it prioritised literal features over the ‘poetic’ ones, and eliminated almost all ambiguities (Simecek, 2015). The definition from David Bordwell seems more appropriate for the project: Narrative can be broadly considered a trans medium or preverbal phenomenon, something more basic and conceptual – a vehicle for making sense of anything we encounter (Bordwell, 2012). With that, creating a narrative is dissected into two elements: things we encounter, and sense-making processes.
The digital turn of audiovisual archives has provided everything we need for the “things we encounter” – with more than ever freedom of manipulation, depth of understanding, and degree of granularity thanks to numerous and diverse existing and potential descriptors. All these sliced, connected, and well-described contents formed the tiny universe to encounter.
What’s left is the sense-making processes, which, in the scope of the project, are the various museum experiences – constructed by experimental interfaces, as well as immersive interactions. With delicate control of the sense-making processes, various narratives can be constructed – traditional storytelling is formed by a linear experience with no interaction or alternative interfaces for a small curated collection of contents, whereas an emergent narrative to explore the plurality of the materials can be formed by simply providing interfaces and interactions with utmost freedom to explore the granular and connected contents. However, the analysis of interactions, interfaces, and experiences, although being another main focus for the Narrative from the long tail, is not stressed in this post.
=====
References:
- Padilla, T., 2017. On a collections as data imperative.
- Fickers, A., Snickars, P. and Williams, M.J., 2018. Editorial Special Issue Audiovisual Data in Digital Humanities. VIEW Journal of European Television History and Culture, 7(14), pp.1–4.
- Tesic, J., 2005. Metadata practices for consumer photos. IEEE MultiMedia, 12(3), pp.86-92.
- Brock, D. 2022. A MUSEUM’S EXPERIENCE WITH AI. Available at: https://computerhistory.org/blog/a-museums-experience-with-ai/ (Accessed: 20 Jan 2022).
- Broadwell, P. and Tangherlini, T.R., 2021. Comparative K-Pop Choreography Analysis through Deep-Learning Pose Estimation across a Large Video Corpus. DHQ: Digital Humanities Quarterly, 15(1).
- Fragkiadakis, M., Nyst, V.A.S. and van der Putten, P.W.H., 2021. Towards a user-friendly tool for automated sign annotation: identification and annotation of time slots, number of hands, and handshape. Digital Humanities Quarterly (DHQ), 15(1).
- Rossetto, L., Baumgartner, M., Ashena, N., Ruosch, F., Pernisch, R., Heitz, L. and Bernstein, A., 2021, June. VideoGraph–Towards Using Knowledge Graphs for Interactive Video Retrieval. In International Conference on Multimedia Modeling (pp. 417-422). Springer, Cham.
- Martin, A., 2021. Hearing Change in the Chocolate City: Computational Methods for Listening to Gentrification. DHQ: Digital Humanities Quarterly, 15(1).
- Kramer, M., 2021. What Does A Photograph Sound Like? Digital Image Sonification As Synesthetic AudioVisual Digital Humanities. DHQ: Digital Humanities Quarterly, 15(1).
Graham, S. and Simons, J., 2020. Listening to Dura Europos: An Experiment in Archaeological Image Sonification. Internet Archaeology, (56).- Deldjoo, Y., Quadrana, M., Elahi, M. and Cremonesi, P., 2017. Using mise-en-sc\ene visual features based on mpeg-7 and deep learning for movie recommendation. arXiv preprint arXiv:1704.06109.
- Colavizza, G., Blanke, T., Jeurgens, C. and Noordegraaf, J., 2021. Archives and AI: an overview of current debates and future perspectives. ACM Journal on Computing and Cultural Heritage (JOCCH), 15(1), pp.1-15.
- Gilliland, A.J., 2014. Conceptualizing 21st-century archives. Society of American Archivists.
- Smith, J.R. and Schirling, P., 2006. Metadata standards roundup. IEEE MultiMedia, 13(2), pp.84-88.
- Angelopoulou, A., Tsinaraki, C. and Christodoulakis, S., 2011, September. Mapping MPEG-7 to CIDOC/CRM. In International Conference on Theory and Practice of Digital Libraries (pp. 40-51). Springer, Berlin, Heidelberg.
- Deldjoo, Y., Quadrana, M., Elahi, M. and Cremonesi, P., 2017. Using mise-en-sc\ene visual features based on mpeg-7 and deep learning for movie recommendation. arXiv preprint arXiv:1704.06109.
- Kosch, H., 2002. MPEG-7 and multimedia database systems. ACM SIGMOD Record, 31(2), pp.34-39.
- Thornely, J., 2000. Metadata and the deployment of Dublin Core at State Library of Queensland and Education Queensland, Australia. OCLC Systems & Services: International digital library perspectives.
- Simecek, K., 2015. Beyond narrative: Poetry, emotion and the perspectival view. British Journal of Aesthetics, 55(4), pp.497-513.
- Bordwell, D., 2012. Three dimensions of film narrative. In Poetics of cinema (pp. 97-146). Routledge.